KvantiMOTV on päivitetty Kvantitatiivisen tutkimuksen verkkokäsikirjaksi. Lue päivitetty artikkeli Regressioanalyysi.
Regressioanalyysi
Regressiosuora ja -kerroin
Regressioanalyysin tulosten tulkinta
Usean muuttujan regressioanalyysi
Dummy-muuttujat
Regressioanalyysin rajoitteet
Lähteet
Regressioanalyysin (regression analysis) avulla tutkitaan yhden tai useamman selittävän muuttujan vaikutusta selitettävään muuttujaan. Sen avulla voidaan pyrkiä vastaamaan esimerkiksi siihen, vaikuttaako koulutuksen pituus saadun palkan suuruuteen, ja jos vaikuttaa, niin kuinka voimakas tämä vaikutus on. Regressioanalyysin erityinen etu on, että siinä voidaan tutkia yhtä aikaa monen selittävän muuttujan vaikutusta selitettävään muuttujaan. Tällöin tulokset kertovat, mikä on yksittäisen selittävän muuttujan osuus silloin kun muiden vaikuttavien tekijöiden vaikutus selitettävään muuttujaan on otettu huomioon.
Regressioanalyysi on monipuolinen ja joustava menetelmä muuttujien välisten kausaalisuhteiden tutkimukseen. Sen edellytyksenä on, että selitettävä muuttuja on vähintään välimatka-asteikollinen (katso muuttujien mittaustaso). Selittävät muuttujat ovat yleensä myös vähintään välimatka-asteikollisia, mutta myös luokittelu- ja järjestysasteikollisia muuttujia voidaan sisällyttää analyysiin. Tällöin niistä täytyy tehdä ns. dummy-muuttujia.
Regressiosuora ja -kerroin
Regressioanalyysin perusperiaatteet voidaan esittää havainnollisesti kuvion 1 avulla. Hajontakuviossa on esitetty 15 valtion lukutaidottomuusprosentti ja valtion panostus koulutukseen prosenttiosuutena bruttokansantuotteesta. Jokainen kuvion piste viittaa yhteen maahan. Esimerkiksi Intiassa oli vuonna 1991 lukutaidottomia noin 48 % väestöstä ja maan bruttokansantuotteesta käytettiin 3,3 % koulutusmenoihin. Kannattaa huomata, että kuviossa esitetyt maat ja luvut ovat oikeita, mutta niiden valinta perustui tarkoituksenmukaisuusharkintaan. Näin esitetyt empiiriset tulokset ovat yleistettävyyden kannalta parhaimmassakin tapauksessa vain suuntaa-antavia.
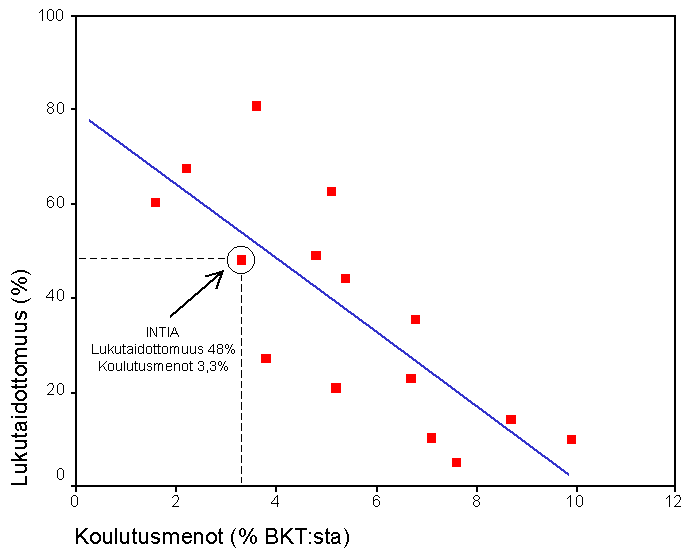
Kuvio 1. Lukutaidottomuusprosentti (1991) ja koulutusmenot (% BKT:sta, 1995). Lähde: Tilastokeskus, Maailma numeroina.
Kuviosta näkee selvästi, miten lukutaidottomuus ja panostus koulutukseen ovat yhteydessä toisiinsa. Mitä suurempi osuus maan bruttokansantuotteesta sijoitetaan koulutukseen, sitä vähemmän maassa on lukutaidottomia. Regressioanalyysin avulla voidaan tutkia, onko näiden kahden muuttujan välinen yhteys tilastollisesti merkitsevä. Lisäksi regressioanalyysi kertoo, kuinka vahva yhteys on, eli kuinka paljon lukutaidottomuus vähenee, kun koulutusmenojen osuus kasvaa.
Kuvioon piirretty viiva on ns. regressiosuora (regression line). Se osoittaa muuttujien välisen yhteyden voimakkuuden. Jos regressiosuora laskee alaspäin, on muuttujilla negatiivinen yhteys ja jos se nousee ylöspäin, on niillä positiivinen yhteys. Mitä lähempänä vaakatasoa suora on, sitä vähemmän muuttujilla on yhteyttä toisiinsa.
Regressiosuora voidaan merkitä kaavan avulla seuraavasti:
Y = a + bX
Kaavassa Y tarkoittaa selitettävän muuttujan arvoa, a on ns. vakiotekijä, X on selittävän muuttujan arvo ja b on regressiokerroin (regression coefficient). Regressiokerroin on regressiosuoran kulmakerroin. Jos se saa negatiivisen arvon, on suora laskeva ja jos regressiokerroin on positiivinen, on suora nouseva. Jos regressiokerroin on nolla, ei muuttujien välillä ole lineaarista eli suoraviivaista yhteyttä. Vakiotekijä kertoo, minkä arvon selitettävä muuttuja saa silloin, kun selittävän muuttujan X arvo on nolla. Se siis kertoo, missä kohtaa regressiosuora leikkaa kuvion y-akselin.
Regressioanalyysin avulla voidaan selvittää kaavan vakiotekijän ja regressiokertoimen arvot. Esimerkiksi kuvion 1 aineiston perusteella saadaan seuraava regressioyhtälö:
Y = 80 - 7,9X
Yhtälön regressiokerroin (eli b:n arvo) on -7,9. Regressiokerroin kertoo, kuinka paljon selitettävä muuttuja muuttuu, kun selittävä muuttuja kasvaa yhden yksikön. Esitetty yhtälö voidaan tulkita seuraavasti. Kun koulutusmenoja lisätään yhdellä prosenttiyksiköllä bruttokansantuotteesta, vähenee lukutaidottomien määrä 7,9 prosenttiyksikköä. Vakiotekijä kertoo, kuinka paljon maassa olisi lukutaidottomia, jos koulutusmenot olisivat nolla eli maassa ei panostettaisi laisinkaan rahaa koulutukseen. Tällöin lukutaidottomia olisi maassa 80 %. Tämä on tietenkin vain hypoteettinen arvio, koska maailmasta tuskin löytyy sellaista maata, missä koulutukseen ei panostettaisi ollenkaan.
Regressiomallin eli -yhtälön pätevyyttä voidaan arvioida sen mukaan, kuinka lähelle kuvion pisteet sijoittuvat regressiosuoraa. Mitä lähempänä suoraa ne sijaitsevat, sitä parempi on regressiomallin selitysvoima ja päinvastoin. Jos kuvion pisteen sijoittuvat hyvin lähelle suoraa, on mallilla hyvä ennustevoima, koska sen avulla voidaan hyvin tarkasti arvioida, mikä on jonkin yksittäisen maan lukutaidottomuusprosentti silloin, kun tiedetään kuinka paljon maassa sijoitetaan koulutukseen. Mitä kauempana pisteet suorasta sijaitsevat, sitä epävarmempia ovat ennusteet.
Yksittäisen havainnon arvon etäisyyttä regressiosuorasta kutsutaan havainnon virhetermiksi tai residuaaliksi (residual). Esimerkiksi kuviosta 1 tiedämme, että Intiassa lukutaidottomuuden taso on 48 %. Regressioyhtälön avulla voidaan myös laskea regressiomallin ennusteen Intian lukutaidottomuudelle. Se saadaan sijoittamalla regressiokaavaan selitettävän muuttujan eli koulutukseen menevien varojen bruttokansantuoteosuus, joka on Intian kohdalla 3,3. Näin saadaan regressiomallin ennusteeksi Intian osalta 53,9 (=80-7,9*3,3). Tämä osoittaa, että regressiomalli ei ole aivan tarkka yksittäisten havaintojen kohdalla. Intian virhetermi mallissa on 48-53,9=-5,9. Mitä suuremmat mallin virhetermit itseisarvoltaan ovat, sitä huonompi ennustearvo regressiomallilla on ja päinvastoin.
Regressioanalyysin tulosten tulkinta
Seuraavaksi käytetään Tilastokeskuksen keräämää Maailma numeroina -aineistoa regressioanalyysin tulosten esittelemiseksi (katso aineiston kuvaus). Selitettävänä muuttujana on maakohtainen elinajan odote eli väestön keskimääräisen odotettavissa olevan eliniän pituus. Elinajan odotteeseen vaikuttaa tietenkin useat eri tekijät, mutta esimerkkiregressioanalyysissa käytetään keskeisenä selittävänä tekijänä HIV-taudin levinneisyyttä. HI-virus ja siitä seuraava AIDS-tauti on 1990-luvulla kääntänyt monessa maassa aikaisemmin kasvussa olleet elinajan odotteet laskuun. Suurimmillaan tämä vaikutus näkyy Afrikassa. Arvioiden mukaan esimerkiksi Zimbabwessa odotettavissa oleva elinikä on laskenut AIDSin vaikutuksesta jopa 26 vuotta (U.S. Bureau of Census 1998). AIDS vaikuttaa elinajan odotteeseen kahdella eri tavalla. Ilman kallista lääkitystä sairaus tappaa aikuiset potilaat nopeasti. Lisäksi sairaus kasvattaa lapsikuolleisuutta, koska taudin voi saada myös HI-virusta kantavalta äidiltä. Näiden kahden tekijän kautta AIDSilla on suuri vaikutus odotettavissa olevaan elinikään.
Aineistossa on 165 maata, joista on saatavilla tiedot sekä elinajan odotteesta että HIV-potilaiden määrästä. Vuonna 1999 eliniän odote vaihteli 36.3 (Malawi) ja 83.5 (Andorra) vuoden välillä. HIV-tapausten yleisyyttä mitataan suhteuttamalla ne väestön kokoon niin, että muuttuja mittaa HIV-tapausten yleisyyttä suhteessa 1000 henkilöön. Tämä muuttuja vaihtelee lähes nollan (esimerkiksi Suomessa 0,21) ja 182 (Botswana) välillä.
Taulukossa 1 on esitetty regressioanalyysin tulokset. Taulukon yläosassa ovat analyysin selittävät muuttujat, niiden regressiokertoimet, t-arvot ja merkitsevyystiedot. Taulukon alaosa sisältää regressiomallin pätevyyden arviointiin sopivia tunnuslukuja.
Taulukko 1. Regressioanalyysi HIV:n yleisyyden vaikutuksesta elinajan odotteeseen
(**p<0,01, n=165).
| Regressiokerroin | t-arvo | Merkitsevyys | |
| Vakio | 68,4** | 91,5 | p<0,001 |
| HIV tapaukset (/1000 henkilöä) | -0,27** | -11,3 | p<0,001 |
| R2 | 0,44 | ||
| Korjattu R2 | 0,44 | ||
| F-testi | 128,0** | p<0,001 | |
| Estimaatin keskivirhe | 8,7 |
Ennen regressiokertoimien varsinaista tulkintaa kannattaa kiinnittää huomiota niiden tilastolliseen merkitsevyyteen. Regressioanalyysin yhteydessä testataan jokaisen selittävän muuttujan osalta onko niillä vaikutusta selitettävään muuttujaan eli eroavatko ne tilastollisesti merkitsevästi nollasta (katso tilastollinen päättely ja hypoteesien testaus). Tällaiseen tarkoitukseen sopiva testimenetelmä on ns. t-testi. Testin tuloksena jokaiselle selittävälle muuttujalle saadaan t-arvo, jonka suuruus ratkaisee sen, voidaanko muuttujan kerrointa pitää nollaa suurempana tilastollisten kriteerien mukaan. Taulukon viimeisessä sarakkeessa on esitetty t-testien merkitsevyystasot. Ne osoittavat, että sekä vakiotermi että HIV-tapausten laajuuden regressiokerroin eroavat tilastollisesti selvästi nollasta. Kaikki regressioanalyysiin sopivat ohjelmat tuottavat nämä tunnusluvut automaattisesti.
Taulukon 1 tulokset siis osoittavat, että HIV-tapausten levinneisyys laskee odotettavissa olevaa elinikää (regressiokertoimen etumerkki on negatiivinen). Kerroin on arvoltaan -0,27, mikä tarkoittaa sitä, että HIV-tapausten suhteellisen osuuden kasvu yhdestä hengestä kahteen henkeen tuhannesta laskee elinajan odotetta 0,27 vuotta. Tämä on suuri muutos. Jos Suomessa (0,21 tapausta / 1000 henkilöä) HIV olisi yhtä yleinen kuin Ranskassa (2,21 / 1000 henkilöä), suomalaisten keskimääräinen elinajan odote olisi noin puoli vuotta matalampi ((2,21-0,21)*0,27=0,54). Jos HIV-tapauksia olisi suhteellisesti yhtä paljon kuin Tansaniassa (39,6 / 1000 henkilöä), suomalaisten elinajan odote olisi peräti 11 vuotta lyhyempi ((39,6-0,21)*0,27=10,6).
Taulukon 1 alalaidassa on esitetty tärkeimmät regressioanalyysin selitysvoimaa kuvaavat testit. Tällaisia testejä on useita, mutta R2-luku ja F-testi ovat yleisemmin käytetyt. R2-luku on regressiomallin selitysosuus. Se kertoo kuinka suuren osuuden selitettävän muuttujan vaihtelusta regressionanalyysin selittävät muuttujat pystyvät selittämään. R2-luku vaihtelee nollan ja yhden välillä. Se saadaan laskemalla selitettävän muuttujan arvojen ja mallin tuottamien ennustearvojen korrelaation neliö. Jos R2-luku on pieni regression selittävät muuttujan pystyvät selittämään vain vähän selitettävän muuttujan vaihtelusta ja päinvastoin. Taulukossa 1 R2-luku on 0.44. Tämä tarkoittaa, että HIV-tapausten levinneisyydellä pystytään siis kohtuullisen hyvin selittämään elinajan odotteen vaihtelua. Regressiomallin avulla 44 % elinajan odotteen vaihtelusta voidaan selittää pelkästään HIV-tapausten suhteellisella määrällä. On kuitenkin huomattava, että selitysosuutta kuvaavat luvut ovat merkityksellisiä nimenomaan regressiomallin asettamassa kontekstissa. Jos elinajan odotetta selitettäisiin lisäksi muilla siihen vaikuttavilla tekijöillä, HIVin levinneisyyden selitysosuus olisi luultavasti pienempi.
Korjattua R2-lukua (adjusted R2) käytetään silloin, kun halutaan verrata kahden regressioanalyysin tuloksia keskenään. Korjattu R2-luku ottaa huomioon mallin sisältämien selittävien muuttujien lukumäärän. Se on arvoltaan aina pienempi tai yhtä suuri kuin varsinainen R2-luku. Korjaus R2-lukuun tarvitaan sen vuoksi, että uusien selittävien muuttujien lisääminen regressioanalyysiin nostaa aina R2-lukua, vaikka nämä lisätyt muuttujat eivät todellisuudessa pystyisikään lisäämään selityskykyä. Silloin kun tarkasteltavana on vain yksi regressiomalli, ei korjatun R2-luvun käyttäminen ole tarpeellista, mutta regressiomalleja verratessa siitä on hyötyä. Jatkossa taulukon 1 regressioanalyysia laajennetaan uusilla muuttujilla. Siksi korjattu R2-luku on raportoitu myös tässä yhteydessä, jotta vertaileminen myöhemmin esitettyihin laajennettuihin regressiomalleihin on mahdollista.
F-testi on tilastollinen testi, joka kertoo pystytäänkö regressioanalyysissa olevilla muuttujilla ylipäänsä selittämään selitettävän muuttujan vaihtelua. Koska se on tilastollinen testi, saadaan sille myös merkitsevyystaso. Taulukossa 1 F-testin tulos on erittäin merkitsevä. Tämä ei sinänsä ole yllätys, koska myös selittävän muuttujan regressiokerroin on tilastollisesti merkitsevä. On kuitenkin mahdollista, että yhdenkään selittävän muuttujan regressiokerroin ei ole tilastollisesti merkitsevä, mutta F-testin tulos on. Tämä tarkoittaa sitä, että regressioanalyysin muuttuja pystyvät yhdessä selittämään selitettävän muuttujan vaihtelua, vaikka yksittäin katsoen ne eivät ole tilastollisesti merkitseviä. Tällaiset tapaukset ovat kuitenkin harvinaisia.
Viimeinen regressiomallin onnistuneisuutta kuvaava tunnusluku on estimaatin keskivirhe (standard error of estimate). Tämä luku ilmoittaa regressiomallin virhetermien keskihajonnan (katso hajontaluvut). Mitä suurempi se on, sitä suurempi on virhetermien hajonta ja samalla sitä pienempi mallin selitysvoima. Estimaatin keskivirheen suuruus riippuu aina regressiomallin hyvyyden lisäksi selitettävän muuttujan mittaluokasta. Taulukossa 1 se on 8,7, mikä on kohtalaisen suuri luku, kun se suhteutetaan elinajan odotteen vaihteluväliin (36-84 vuotta). Tämä osoittaa, että HIV-tapausten yleisyydestä tietyssä maassa ei pystytä kovinkaan tarkasti ennustamaan maan väestön odotettavissa olevaa keskimääräistä elinikää.
Usean muuttujan regressioanalyysi
Edellisissä regressioanalyysin esimerkeissä oli vain yksi selittävä muuttuja. Regressioanalyysin etu on kuitenkin se, että siihen voi sisällyttää useita selittäviä muuttujia yhtäaikaisesti. Tällöin muuttujien regressiokertoimet kertovat, kuinka paljon selitettävän muuttujan arvo muuttuu, kun selittävän muuttujan arvo muuttuu yhdellä yksiköllä ja kaikkien muiden muuttujien arvo pysyy samana. Toisin sanoen usean muuttujan regressioanalyysissa regressiokertoimet ilmoittavat selittävän muuttujan vaikutuksen selitettävään muuttujaan niin, että muiden mallin muuttujien vaikutus on vakioitu.
Kahden selittävän muuttujan regressioanalyysin kaava voidaan esittää seuraavasti:
Y = a + b1X1 + b2X2
Kaavassa Y on selitettävän muuttujan arvo, a vakiotekijä, X1 ja X2 selittävät muuttujat sekä b1 ja b2 niiden regressiokertoimet.
Usean muuttujan regressioanalyysin kuvaamiseen voidaan käyttää edellistä esimerkkiä HIV-taudin yleisyyden ja elinajan odotteen yhteydestä. HIV ei ole ainoa tekijä, joka vaikuttaa keskimääräiseen odotettavissa olevaan elinikään. Yksi tällainen tekijä on maan yleinen taloudellinen kehitystaso, joka vaikuttaa muun muassa siihen, kuinka paljon lääkäreitä ja sairaaloita maassa on, kuinka paljon on mahdollista käyttää kalliita lääkkeitä jne. Usein taloudellista kehitystasoa mitataan suhteuttamalla maan bruttokansantuote väkilukuun. Seuraavaksi tämä muuttuja lisätään HIV-taudin yleisyyden lisäksi regressioanalyysiin. BKT-muuttuja mittaa henkeä kohden laskettua bruttokansantuotetta vuonna 1997 tuhansina dollareina (eli 1000 US$/henkilöä). Muuttuja vaihtelee välillä 0,09 (Kongon demokraattinen tasavalta) ja 40,6 (Brunei).
Taulukossa 2 on esitetty tämän regressioanalyysin tulokset. Uuden muuttujan lisääminen analyysiin ei muuttanut paljoakaan HIV-muuttujan kerrointa. Tämä tarkoittaa sitä, että HIV-taudin yleisyydellä on selvä vaikutus elinajan odotteeseen, vaikka maan taloudellinen kehitystaso otetaankin analyysissa huomioon. BKT-muuttujan regressiokerroin on myös tilastollisesti merkitsevä ja sen arvo on 0,57. Kertoimen tulkinta kertoo, että maan henkeä kohden lasketun bruttokansantuotteen kasvaessa 1000 yhdysvaltain dollarilla elinajan odote kasvaa noin puolella vuodella, jos maan HIV-tilanne pysyy samana.
Taulukko 2. Regressioanalyysi HIV:n yleisyyden vaikutuksesta elinajan odotteeseen
(**p<0,01, n=165).
| Regressiokerroin | t-arvo | Merkitsevyys | |
| Vakio | 64,4** | 87,0 | p<0,001 |
| HIV tapaukset (/1000 henkilöä) | -0,23** | -11,6 | p<0,001 |
| BKT /henkilö | 0,57** | 9,44 | p<0,001 |
| R2 | 0,64 | ||
| Korjattu R2 | 0,63 | ||
| F-testi | 143,2** | p<0,001 | |
| Estimaatin keskivirhe | 7,04 |
Taulukon 2 korjattu R2-luku luku osoittaa, että BKT-muuttujan lisääminen regressiomalliin paransi mallin selityskykyä huomattavasti verrattuna Taulukon 1 tuloksiin. Taulukossa 1 korjattu R2-luku on 0,44 ja taulukossa 2 vastaava tunnusluku on 0,63. Lisäksi estimaatin keskivirhe pieneni 8,7:stä 7,0:an. Nämä molemmat tunnusluvut kertovat, että käyttämällä BKT-muuttujaan HIV-muuttujan ohella analyysissa, pystytään eri maiden odotettavissa olevaa elinikää ennustamaan paremmin kuin tyytymällä ainoastaan HIV-muuttujan käyttöön.
Dummy-muuttujat
Dummy-muuttujaksi kutsutaan sellaista muuttujaa, joka voi saada vain kaksi eri arvoa, jotka on koodattu nollaksi ja yhdeksi. Tyyppiesimerkki tällaisesta muuttujasta on perinteisesti ollut vastaajan sukupuoli, mutta vaihtoehtoja on helppo keksiä lisää (onko vastaaja opiskelija vai ei, onko maa liittovaltio vai ei jne.) Dummy-muuttujien avulla regressioanalyysiin voidaan helposti sisällyttää luokittelu- tai järjestysasteikollisia muuttujia.
Oletetaan, että afrikkalaisissa maissa elinajan odote on jostakin syystä alhaisempi kuin muissa maissa. Tätä hypoteesia voi tutkia lisäämällä regressioanalyysiin dummy-muuttujan, joka saa arvon yksi silloin kun maa sijaitsee Afrikassa ja muutoin arvoksi tulee nolla. Kaavan avulla tämä voidaan esittää seuraavasti:
Y = a + b1X1 + b2X2 + b3X3
Kaavassa X3 on uusi dummy-muuttuja, joka saa arvon yksi silloin kun kyseessä on afrikkalainen maa. Muut muuttujat ovat samat kuin edellisessä esimerkissä.
Dummy-muuttujien regressiokertoimien tulkinta on erittäin yksinkertaista. Kerroin ilmoittaa, kuinka muuttujalla arvon yksi saava havaintoryhmä eroaa niistä havainnoista, jotka saavat arvon nolla. Jos kerroin on positiivinen, se ilmaisee kuinka paljon suurempi elinajan odote on Afrikassa kuin Afrikan ulkopuolisissa maissa. Jos se on negatiivinen, kertoo se kuinka paljon lyhyempi elinikä Afrikassa on.
Taulukko 3 sisältää tulokset regressioanalyysista, jossa Afrikkaa koskeva dummy-muuttuja on mukana. Se saa arvon -11, mikä tarkoittaa sitä, että Afrikan maissa elinajan odote on noin 11 vuotta lyhyempi kuin muissa maissa, vaikka HIVin levinneisyys ja maan taloudellisen kehityksen tila on otettu huomioon. Lisäksi kannattaa huomioida, että HIV-muuttujan kerroin pieneni huomattavasti dummy-muuttujan lisäyksen jälkeen. Tässä tapauksessa dummy-muuttujan käyttö ei itse asiassa selitä miksi elinikä on Afrikassa lyhyempi kuin muualla, vaan se ainoastaan tuo esille tämän empiirisen yhdenmukaisuuden. Analyysin seuraavana askeleena tulisikin pohtia, mitkä mahdolliset elinikään vaikuttavat tekijät ovat yleisempiä Afrikassa kuin muualla maailmassa. Tämän teoreettistakin pohdintaa vaativan arvioinnin jälkeen analyysiin voitaisiin ehkä lisätä uusia muuttujia tulosten parantamiseksi.
Taulukko 3. Regressioanalyysi HIV:n yleisyyden vaikutuksesta elinajan odotteeseen
| Regressiokerroin | t-arvo | Merkitsevyys | |
| Vakio | 67,3** | 98,8 | p<0,001 |
| HIV tapaukset (/1000 henkilöä) | -0,14** | -7,1 | p<0,001 |
| BKT /henkilö | 0,44** | 8,4 | p<0,001 |
| Afrikkaa kuvaava dummy-muuttuja | -11,02** | -8,76 | p<0,001 |
| R2 | 0,76 | ||
| Korjattu R2 | 0,75 | ||
| F-testi | 165,7** | p<0,001 | |
| Estimaatin keskivirhe | 5,81 |
Dummy-muuttujia voidaan käyttää myös tilanteessa, jossa laatu- tai järjestysasteikon muuttuja saa useampia kuin kaksi vaihtoehtoa. Tällaisessa tilanteessa yleinen periaate on, että uusia dummy-muuttujia täytyy luoda yksi vähemmän kuin laatu- tai järjestysasteikon muuttujassa on vastausvaihtoehtoja. Jos esimerkiksi laatueroasteikon muuttuja voi saada neljä eri arvoa, täytyy regressioanalyysia varten luoda kolme uutta dummy-muuttujaa.
Oletetaan, että tutkija haluaa regressioanalyysin avulla selvittää henkilöiden iän ja koulutuksen vaikutusta heidän palkkatasoonsa. Koulutus on mitattu kolmiasteisella mittarilla, jonka vaihtoehdot ovat peruskoulu, keskiasteen tutkinto ja korkeakoulututkinto. Regressioanalyysin tarpeisiin tästä muuttujasta täytyy luoda kaksi uutta dummy-muuttujaa. Ensimmäinen muuttuja voisi olla peruskoulu-dummy, joka saa arvon yksi jos vastaaja on suorittanut vain peruskoulun. Muutoin muuttuja saa arvon nolla. Toinen muuttuja olisi keskiaste-dummy, joka saa arvon yksi silloin kun vastaajalla on keskiasteen tutkinto ja arvon nolla muutoin. Tutkija laskee regressioanalyysin, jossa selitettävänä muuttujana on vastaajan palkan suuruus markkoina ja selittävinä muuttujina vastaajan ikä sekä kaksi edellä mainittua dummy-muuttujaa.
Useamman dummy-muuttujan tapauksessa niiden regressiokertoimien tulkinta tulee hiukan hankalammaksi, koska ne täytyy tulkita toisiinsa suhteuttaen. Oletetaan, että regressioanalyysin tuloksissa peruskoulu-dummyn regressiokerroin on -5000 ja keskiaste-dummyn -2000. Nämä kertoimet tulee tulkita suhteessa korkeakoulututkinnon suorittaneiden palkkaan. Ne kertovat, että ainoastaan peruskoulun suorittaneiden palkka on keskimäärin 5000 mk pienempi kuin korkeakoulun suorittaneiden palkat. Keskiasteen tutkinnon suorittaneiden keskimääräinen palkka on 2000 mk pienempi kuin korkeakoulututkinnon suorittaneiden. Dummy-muuttujien regressiokertoimet ilmoittavat siis ryhmän keskimääräisen poikkeaman siitä ryhmästä, jolle ei tehty omaa dummy-muuttujaa.
Päätökset siitä, mille vastausvaihtoehdoille omat dummy-muuttujat luodaan ja mikä vaihtoehto jätetään analyysista pois, eivät ole kovin ratkaisevia. Ne toki vaikuttavat dummy-muuttujien regressiokertoimien arvoihin, mutta niistä tehtävät tulkinnat ovat kuitenkin samoja. Jos edelliseen regressiomalliin olisikin lisätty keskiaste- ja korkeakoulu-dummyt, olisivat niiden regressiokertoimet olleet +3000 ja +5000 mk. Ne siis kertovat, että korkeakoulun käyneiden ja peruskoulun käyneiden keskimääräinen ero palkoissa on 5000 mk sekä korkeakoulun käyneiden ja keskiasteenkoulutuksen saaneiden 2000 mk.
Lähteet
U.S Bureau of Census (1998): World Population Profile: 1998. Washington.