KvantiMOTV on päivitetty Kvantitatiivisen tutkimuksen verkkokäsikirjaksi.Katso päivitetyt SPSS-harjoitukset.
Logistinen regressioanalyysi - SPSS-harjoitus 1
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta MOTV-ympäristössä, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Tässä demonstraatiossa käytetään vuoden 1996 World Values Survey tutkimuksen Suomen osa-aineistoa.
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Logistinen regressioanalyysi
» osaWVS-aineisto | Harjoitusaineistot
Regressiomalleissa, joissa selitettävä muuttuja on dikotominen (kaksiluokkainen, arvoja 0 ja 1 saava), tulkitaan selitettävän muuttujan odotusarvon riippuvan selittävistä muuttujista (Xk). Erona tavanomaiseen regressioanalyysin on se, että muuttujien välisten riippuvuuksien ei tarvitse olla nimenomaan lineaarisia, vaan myös muunlaiset riippuvuussuhteet (esimerkiksi eksponentiaalinen tai logaritminen) kelpaavat. Todennäköisyyttä sille, että havainto saa arvon 0 (tai 1) selitettävässä muuttujassa, arvioidaan logistisella mallilla:
exp(u)/(1+exp(u)), missä u = a + b1x1 + b2x2 +...+ bkxk
Kaavassa k on selittävien muuttujien lukumäärä, a on vakiotermi ja bi:t regressiokertoimia.
Logistisen regressioanalyysin esimerkissä tutkitaan, mitkä tekijät vaikuttavat suomalaisten protektionismin kannatukseen. Aineistossa on kysymys, jossa vastaajien piti valita kahdesta vaihtoehdosta mielestään parempi (v133, arvo 9 = "Ei osaa sanoa" koodataan puuttuvaksi tiedoksi).
Nämä vaihtoehdot olivat:
- Muissa maissa valmistettuja tuotteita voidaan tuoda tänne ja myydä täällä, jos ihmiset haluavat ostaa niitä ja
- Ulkomaisten tuotteiden myynnille Suomessa pitäisi olla enemmän esteitä, jotta voitaisiin suojella tämän maan ihmisten työpaikkoja.
Näistä jälkimmäinen edustaa protektionistista ajattelutapaa.
Selitettävä muuttuja on kaksiluokkainen, joten logistisen regressioanalyysin avulla voidaan tutkia, mitkä tekijät vaikuttavat vastaajien todennäköisyyteen valita protektionistinen vaihtoehto.
Analyysin selittäjinä käytetään viittä eri muuttujaa:
- Demografisista muuttujista mukana ovat vastaajan ikä (v216) ja sukupuoli (v214, koodattu seuraavasti: mies=0, nainen=1).
- Vastaajan tulotasoa mitataan 10-luokkaisella muuttujalla (v227, arvo 98 koodataan puuttuvaksi tiedoksi), jossa suuret arvot tarkoittavat korkeampia tuloja.
- Asennemuuttujista mukana on vastaajien ylpeys suomalaisuudestaan (v205, arvo 9 koodataan puuttuvaksi tiedoksi). Se on mitattu neliportaisella asteikolla, jossa pienet arvot kuvaavat suurempaa ylpeyttä.
- Lisäksi mallissa on mukana muuttuja, joka kuvaa vastaajan sijoittumista politiikan vasemmisto-oikeisto -ulottuvuudella (v123, arvot 98 ja 99 koodataan puuttuvaksi tiedoksi). Se saa arvoja yhdestä kymmeneen pienten arvojen kuvastaessa sijoittumista vasemmalle.
SPSS ohjelmistossa logistinen regressioanalyysi aloitetaan valikosta Analyze - Regression - Binary Logistic...
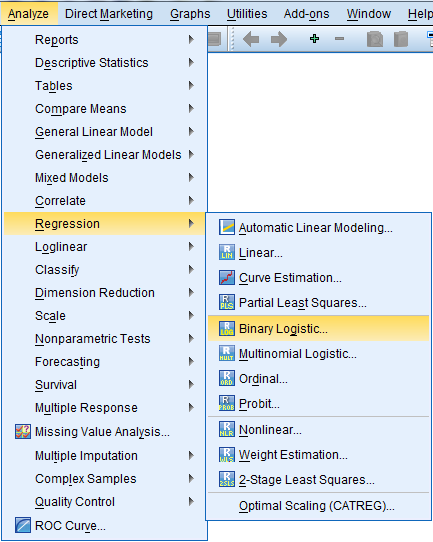
Seuraavassa ikkunassa valitaan selitettävä muuttuja (Dependent) ja selitettävät muuttujat (Covariates). Method-valinnalla valitaan käytettävä selittävien muuttujien lisäystapa regressiomalliin. Valittavana on suora (Enter) muuttujien lisäys sekä useita askeltavia valintamalleja. Askeltavissa menetelmissä muuttujat lisätään tai poistetaan mallista sen mukaan mikä valinta kasvattaa mallin selitysastetta parhaiten. SPSS sisältää seuraavat menetelmät:
- Forward: Lähdetään tyhjästä mallista ja lisätään se muuttuja, joka parantaa selitysastetta eniten. Lopetetaan sitten, kun selitysaste ei enää parane.
- Backward: Lähdetään kaikista selittävistä muuttujista ja poistetaan se muuttuja, joka vähiten heikentää selitysastetta.
- Stepwise: Sama kuin Forward, mutta tässä jo lisätty muuttuja voidaan poistaa myöhemmässä vaiheessa.
Eri menetelmät eivät välttämättä päädy samaan selittävien muuttujien joukkoon.
Klikkaamalla OK saamme tulokseksi logistisen regressioanalyysin tulokset.
Tulosten tulkinta
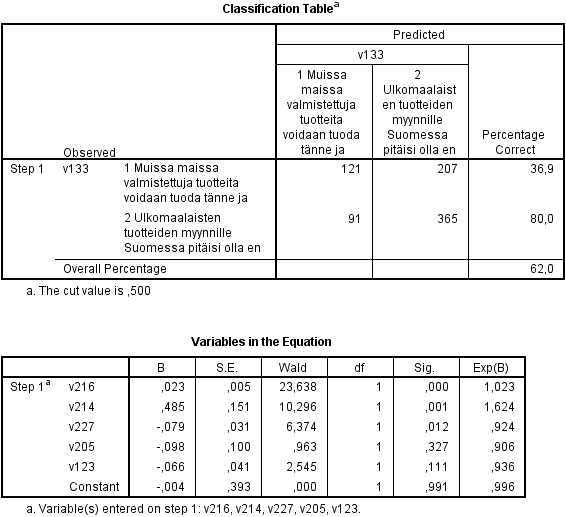
Taulun Variables in the Equation sarakkeessa B luetellaan regressiokertoimet. Regressiokertoimia vastaavat testit perustuvat Wald'in testisuureeseen, joka saadaan jakamalla kerroin (B) keskivirheellään (S.E.) ja korottamalla ko. osamäärä toiseen potenssiin. Siis esim. Waldin testisuure ikä-muuttujan (V216) kertoimelle on:
Wald = (0.023/0.005)^2 = 23.638
Waldin testisuure on ![]() -jakautunut vapausastein 1. (Mikäli selittävä muuttuja on luokkamuuttuja, on vapausaste m - 1, missä m on luokkien määrä.) Sig.-sarakkeesta näemme Waldin-testisuureen arvoa vastaavan p-arvon. Toteamme, että selittävien muuttujien ikä (V216), sukupuoli (V214) ja tuloluokka (V227) regressiokertoimet ovat tilastollisesti merkitsevästi (alfa = 0.05) nollasta poikkeavia. Waldin testi on suurilla regressiokertoimien arvoilla epäluotettava. Tällöin nimittäin estimoitu keskivirhe on liian suuri, joten Wald-testisuure itse on liian pieni, ja tämä saattaa johtaa siihen, että nollahypoteesi: B_i = 0 jää voimaan silloinkin, kun se pitäisi hylätä. Suositeltava vaihtoehto Waldin testille suurilla kertoimien arvoilla on testata, muuttuuko logaritminen uskottavuus (log likelihood), kun kyseinen muuttuja lisätään malliin.
-jakautunut vapausastein 1. (Mikäli selittävä muuttuja on luokkamuuttuja, on vapausaste m - 1, missä m on luokkien määrä.) Sig.-sarakkeesta näemme Waldin-testisuureen arvoa vastaavan p-arvon. Toteamme, että selittävien muuttujien ikä (V216), sukupuoli (V214) ja tuloluokka (V227) regressiokertoimet ovat tilastollisesti merkitsevästi (alfa = 0.05) nollasta poikkeavia. Waldin testi on suurilla regressiokertoimien arvoilla epäluotettava. Tällöin nimittäin estimoitu keskivirhe on liian suuri, joten Wald-testisuure itse on liian pieni, ja tämä saattaa johtaa siihen, että nollahypoteesi: B_i = 0 jää voimaan silloinkin, kun se pitäisi hylätä. Suositeltava vaihtoehto Waldin testille suurilla kertoimien arvoilla on testata, muuttuuko logaritminen uskottavuus (log likelihood), kun kyseinen muuttuja lisätään malliin.
Kertoimet (B) eli riskit on helpointa tulkita odds ratio -käsitteen (ristitulosuhde) avulla, jota ylläolevassa tulostuksessa vastaa sarake Exp(B). Tämä osoittaa kutakin muuttujaa vastaavan riskin muutoksen: Jos yksittäisen havainnon jonkin muuttujan arvo lisääntyy yhdellä yksiköllä, niin kyseisen havainnon uusi riski saadaan kertomalla alkuperäinen riski vastaavalla odds ratio -kertoimella. Jos esimerkiksi ikä lisääntyy yhdellä vuodella, niin uusi odds saadaan vanhasta kertomalla se luvulla 1.023, eli toisin sanoen riski kasvaa 2.3 prosenttia. Jokainen ikävuosi siis kasvattaa todennäköisyyttä valita protektionistinen vaihtoehto 2.3 prosentilla.
Taulukosta Classification Table voidaan arvioida mallin hyvyyttä eli oikein luokiteltujen havaintojen määrä. Mallin antaman ennusteen P avulla voidaan kukin havainto luokitella kahteen ryhmään: Jos P < 0.5, niin ennustetaan, että havainto kuuluu ryhmään 0 ja vastaavasti, jos P > 0.5, niin ennustetaan, että havainto kuuluu ryhmään 1. Ei protektionisessa ryhmässä oikein luokiteltiin vain 36.9 prosenttia ja vastaavasti protektionistisessa ryhmässä 80 prosenttia. Kokonaisuudessaan oikein luokiteltiin 62 prosenttia havainnoista.